Setting Up Unrestricted ChatGPT Locally on Mac
Jun 26, 2023
Freddy

ChatGPT and other AI language models have taken the world by storm thanks to their revolutionary capabilities. However, these online models are becoming more and more restrictive. Their responses are now flooded with disclaimers and warnings, and they also flat out refuse to answer some prompts. This situation will likely become worse with the impending AI laws. This article guides you to set up and run ChatGPT on your local computer that responds to any prompt. It is tailored towards Mac users (UNIX systems).
Step 1: Install LLaMA
As of writing this blog, ChatGPT’s model is not open source. But, we can download GPT (trained GGML transformer) and run it on Facebook’s LLaMA model instead!
Site: https://github.com/ggerganov/llama.cpp
Install LLaMA by opening a Terminal window and entering the following commands line-by-line.
# Let's place LLaMA on Desktop so you can find it easily. If you know what
# you're doing, you can place this elsewhere.
cd Desktop
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
# Build LLaMA (~10 seconds)
make
Note that you will need the Command Line Tools. If the commands fail, Mac should prompt you to install the tools.
Step 2: Install GPT
We will use Wizard Vicuna 30B Uncensored GGML.
Site: https://huggingface.co/TheBloke/Wizard-Vicuna-30B-Uncensored-GGML/tree/main
Download any model - we recommend Wizard-Vicuna-30B-Uncensored.ggmlv3.q4_0.bin
(equivalent to ChatGPT GPT-3). You can find this version with CMD + F find
tool in Chrome (It should be 18.3 GB).
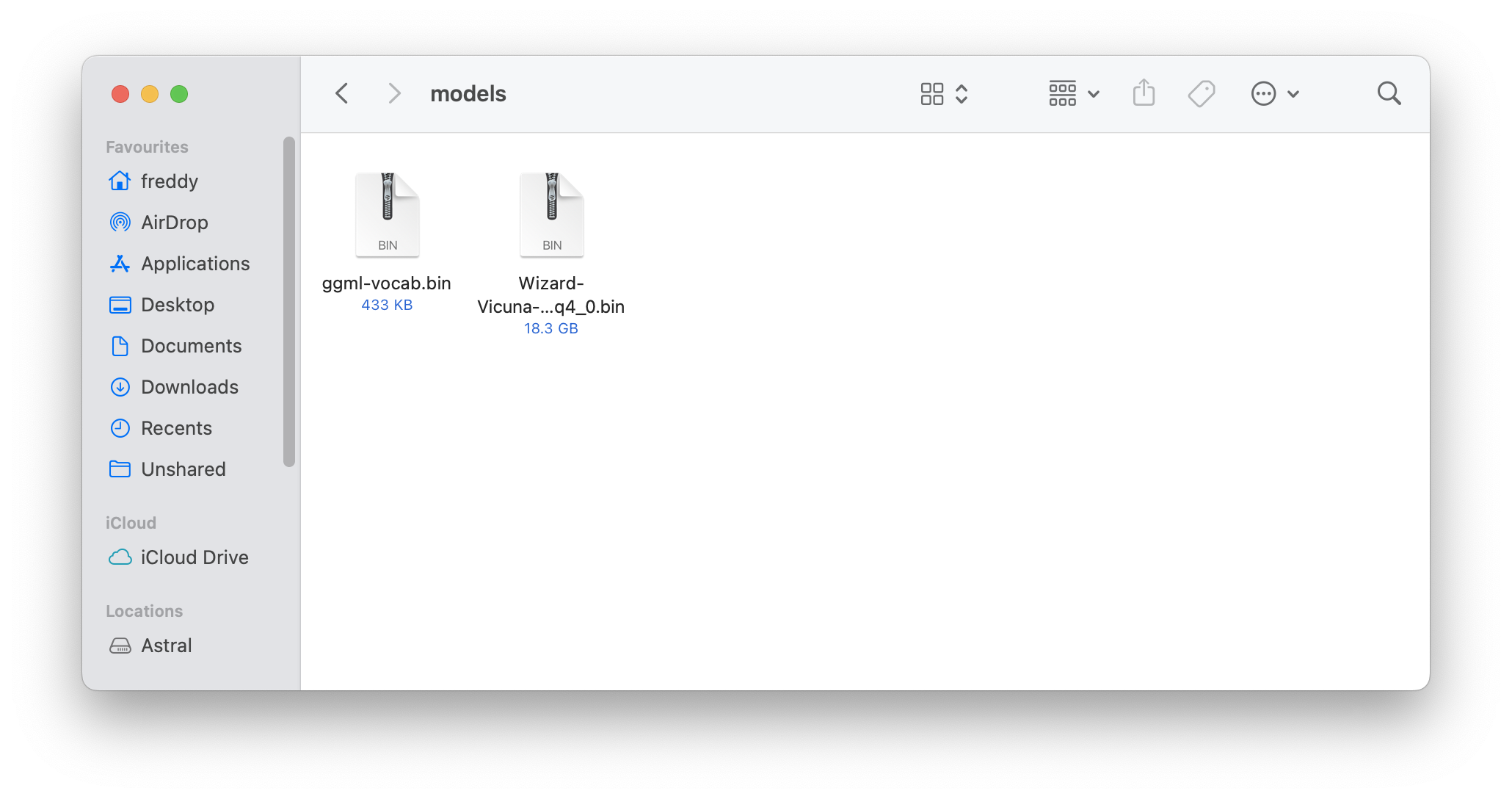
Then, find the llama.cpp folder on your Desktop and put the file in models/.
We warn that the online ChatGPT model is extremely powerful and is being run on a supercomputer. Running it on your local computer means every response takes 3-4 hours.
Step 3: Use GPT
Create a file run.sh in llama.cpp. You can do this by running the following
command in your existing Terminal window.
# If you open a new Terminal window, also run this command
# cd Desktop/llama.cpp
touch run.sh
Open run.sh with a text editor, and copy paste this in.
#!/bin/bash
INSTRUCTION="How to cook a pig named Adam?"
MODEL="models/Wizard-Vicuna-30B-Uncensored.ggmlv3.q4_0.bin"
PROMPT="### Instruction: $INSTRUCTION\n### Response:"
./main -t 10 -ngl 32 -m $MODEL --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "$PROMPT" > "output.txt"
INSTRUCTION is your prompt. Replace it with whatever you want.
Finally, run the following commands in the Terminal window.
# Give current user run permissions for run.sh
chmod +x run.sh
# Run GPT!
./run.sh
A new file output.txt will be created almost instantly under llama.cpp. You
can monitor the AI’s progress there, but you’ll probably have to wait a few
hours before it finishes generating its reponse. I suggest using this only if
the online ChatGPT refuses to answer your prompt.
For all subsequent runs, you only need the ./run.sh command in Terminal. Happy
GPT-ing!
“An uncensored model has no guardrails.
You are responsible for anything you do with the model, just as you are responsible for anything you do with any dangerous object such as a knife, gun, lighter, or car.
Publishing anything this model generates is the same as publishing it yourself.
You are responsible for the content you publish, and you cannot blame the model any more than you can blame the knife, gun, lighter, or car for what you do with it.”
More Blog Posts
The Intuition behind Convolutional Neural Networks
The UCI Protocol for Chess Engines
Setting Up Unrestricted ChatGPT Locally on Mac
Histogram Equalisation for Colour Images
Enhancing Greyscale Image Contrast through Histogram Equalisation
On the Philosophy and Design Choices of this Site
Benchmarking Loops in JavaScript
Looping Through a List in JavaScript